Lokale KI im Unternehmen, vielleicht auch ein Ansatz für Dich? 🚀
Im Accounting & Controlling stehen wir oft vor einem fundamentalen Dilemma: Tools wie ChatGPT, Claude oder Gemini sind extrem leistungsfähig, aber für unsere sensibelsten Daten schlicht tabu. Bilanzen, Erfolgsrechnungen, Personalkosten oder Mandantendaten oder strategische Planungen haben auf externen Servern von US-Anbietern nichts zu suchen. Punkt.
Meine Ausgangslage: Lokale KI auf dem Laptop
Ich habe daher schon vor einem Jahr damit begonnen, mit lokalen Lösungen zu experimentieren. Ich selbst arbeite seit längerem mit lokalen KI-Modellen wie Qwen, Mistral, Llama oder DeepSeek. Das läuft auf meinem Laptop dank einer leistungsstarken NVIDIA-Grafikkarte hervorragend. Keine Daten verlassen das Gerät, alles bleibt lokal.
Die Vorteile sind offensichtlich:
- Volle Datenkontrolle – nichts geht nach aussen
- Keine Abhängigkeit von Internet-Verbindungen
- Keine laufenden API-Kosten
- Compliance-konform, da Daten das Gerät nie verlassen
So gut dieses Setup für mich als Einzelnutzer funktioniert, so schnell stösst es an Grenzen, wenn wir über Skalierung nachdenken.
Das Problem der “Insel-Lösung”
Die KI läuft isoliert auf meiner Hardware. Wenn ich Kollegen Zugriff geben möchte, wird es kompliziert. Nicht jeder Kollege hat eine High-End-Grafikkarte im Laptop. Und nicht jeder soll vor allem auf alle selbstgebauten “Mini-Agents” oder RAG-Systeme (Retrieval Augmented Generation) zugreifen dürfen.
Ein konkretes Beispiel aus meiner Praxis: Ich habe einen kleinen Agent gebaut, der sich mit unserem Pacioli (Export aller Buchungsdaten) verbindet, Bilanzen analysiert, Kennzahlen berechnet und Fragen zur Buchhaltung beantworten kann.
Die Fragen, die sich stellen:
- Wie können Teamkollegen diese Tools nutzen, ohne eigene Hardware anzuschaffen?
- Wie steuere ich, wer welchen Agent nutzen darf?
- Wie integriere ich das in unsere bestehende IT-Landschaft?
- Wie vermeide ich separate Passwörter und Zugänge?
Es gibt mittlerweile kommerzielle Anbieter, die solche Infrastrukturen “schlüsselfertig” verkaufen, dies aber natürlich nicht ganz kostenlos und ich bin dann meistens wieder auf einem externen Server bei diesem Host. Bevor wir jedoch Budget für externe Lösungen freigeben, wollte ich einen alternativen Weg testen: Eine professionelle Eigenbau-Lösung mit Open-Source-Mitteln, aber voll integriert in unsere Firmen-IT.
Die Basistechnologie: Docker, Ollama & OpenWebUI
Mein bewährtes Setup basiert auf drei Säulen, die alle Open-Source und kostenlos verfügbar sind und mittlerweilen von einer grossen Community erfolgreich genutzt werden:
Docker
Docker ist eine Containerisierungs-Plattform. Stellen Sie sich Container wie abgeschlossene “Boxen” vor, in denen Anwendungen laufen, isoliert vom Rest des Systems. Das macht die Installation reproduzierbar und das Management einfacher. Für Finanzverantwortliche relevant: Docker ist in vielen IT-Abteilungen bereits Standard und wird von der IT akzeptiert.
Ollama
Ollama ist das Werkzeug, um Sprachmodelle (LLMs) lokal auszuführen. Es abstrahiert die technische Komplexität und macht es einfach, verschiedene Modelle wie Llama 3, Mistral, Qwen oder DeepSeek auf eigener Hardware zu starten. Ollama kümmert sich um das Laden der Modelle, die GPU-Nutzung und die Bereitstellung einer API, über die andere Anwendungen mit der KI kommunizieren können.
OpenWebUI
OpenWebUI ist die benutzerfreundliche Chat-Oberfläche, die ChatGPT sehr ähnlich sieht. Das senkt die Einstiegshürde für Kollegen massiv, die Oberfläche ist intuitiv, und niemand muss sich an eine völlig neue Umgebung gewöhnen.
Der wirklich grosse Vorteil dieser Kombination: In Verbindung mit Python lassen sich nicht nur Chats führen, sondern echte Applikationen bauen, kleine “Agents”, die spezifische Aufgaben übernehmen, ohne dass Daten abfliessen.
Schritt-für-Schritt: Vom Laptop zum Team-Server
Um diese Infrastruktur für Kollegen nutzbar zu machen, habe ich, mit technischer Unterstützung von Claude, folgendes Setup implementiert. Das Ziel: Eine sichere Umgebung mit Zugriffskontrolle, integriert in unsere bestehende Microsoft-Infrastruktur. Und ich muss wirklich sagen, dass Claude einem bei der Installation wirklich gut guidet. Zusammen mit Ihrer IT werden Sie das ohne Weiteres auch schaffen können!
Schritt 1: Installation im Netzwerk
Anstatt alles auf dem Laptop zu behalten, habe ich OpenWebUI auf einem Server im Firmennetzwerk installiert. Das ist die Schnittstelle, die die Kollegen später im Browser sehen. Der Server muss keine Monster-Hardware haben, er dient primär als “Vermittler” zwischen den Nutzern und der eigentlichen Rechenleistung.
Technischer Hinweis: Die Installation erfolgt via Docker-Compose. Das bedeutet: Eine einzige Konfigurationsdatei beschreibt das gesamte Setup. Das macht Wiederherstellung, Updates und Dokumentation deutlich einfacher als bei klassischen Installationen.
Schritt 2: Die Verbindung zur “Intelligenz”
Diesen Server habe ich mit meinem leistungsstarken Laptop verbunden, auf dem die eigentlichen Modelle (via Ollama) laufen. Die Kommunikation erfolgt über das interne Netzwerk, verschlüsselt und ohne Kontakt zum Internet.
Hinweis für die Praxis: In einem echten Produktiv-Szenario würde man natürlich auch die Modelle direkt auf einem Server mit entsprechender GPU-Hardware laufen lassen. Für meinen Proof of Concept reichte die Verbindung Server (UI) ↔ Laptop (Rechenpower) jedoch völlig aus. Das zeigt auch: Man kann klein anfangen und später skalieren.
Typische Hardware-Anforderungen für lokale LLMs:
- Minimum: 16 GB RAM, GPU mit 8 GB VRAM (kleinere Modelle)
- Empfohlen: 32 GB RAM, GPU mit 16-24 GB VRAM (grössere Modelle) -> Das ist mein aktueller Setup mit 16 GB VRAM – NVIDIA RTX 4090
- Enterprise: Dedizierter Server mit professioneller GPU (NVIDIA A100, H100)
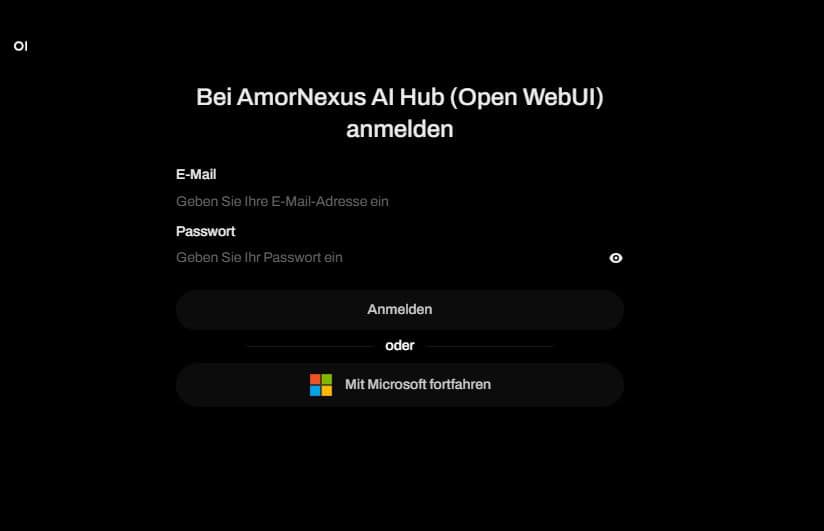
Schritt 3: Der Schlüssel zur Sicherheit – Microsoft Login (SSO)
Das war der wichtigste Schritt für die Sicherheit und Akzeptanz im Team. In OpenWebUI habe ich den Microsoft-Login aktiviert (via OIDC/OAuth). Das bedeutet: Es gibt keine separaten “KI-Passwörter”. Die Kollegen melden sich einfach mit ihrem bestehenden Microsoft-Firmenaccount an.
Warum ist das so wichtig?
- Keine separate Benutzerverwaltung nötig
- Single Sign-On (SSO) – ein Login für alles
- Automatische Deaktivierung bei Austritt aus dem Unternehmen
- Audit-Trail über Microsoft-Protokolle
- Erfüllt IT-Sicherheitsanforderungen
- Senkt die Akzeptanzhürde bei Nutzern massiv
Technischer Hintergrund: OpenWebUI unterstützt verschiedene OAuth-Provider. Für die Microsoft-Integration benötigen Sie eine App-Registrierung in Azure AD (Entra ID). Die IT-Abteilung kann das in der Regel innerhalb einer Stunde einrichten. Sie erhalten dann Client-ID und Client-Secret, die in OpenWebUI hinterlegt werden.
Schritt 4: Rollen und Berechtigungen
Sobald die Authentifizierung über Microsoft läuft, können wir in OpenWebUI granular steuern, wer was darf. Über ein Rollenkonzept lässt sich definieren:
- Wer darf auf welchen Chatbot zugreifen? Beispiel: Der Bilanz-Analyse-Agent ist nur für das Controlling sichtbar.
- Wer darf spezielle Python-Applikationen nutzen? Beispiel: Der Vertrags-Assistent ist nur für Legal und Finance freigegeben.
- Welche RAG-Systeme sind für wen sichtbar? Beispiel: Das Dokumenten-Archiv der Geschäftsleitung ist nur für C-Level zugänglich.
- Wer darf neue Agents erstellen? Beispiel: Nur Power-User oder die IT-Abteilung.
Diese Flexibilität ist entscheidend. Nicht jeder braucht Zugriff auf alles und nicht jeder sollte Zugriff haben.
Das Ergebnis: Sichere KI für das Team
Kollegen können nun meine vorab konfigurierten, lokalen KI-Modelle nutzen. Sie loggen sich sicher ein, und alle Eingaben, seien es sensible Excel-Analysen, Strategiepapiere oder Mandantendaten, bleiben im Firmennetzwerk. 🔒
Die Flexibilität: Lokal + Cloud unter einer Oberfläche
Zusätzlich bietet OpenWebUI die Möglichkeit, über eine API auch externe Modelle wie ChatGPT, Gemini oder Claude einzubinden. Falls man für unkritische Aufgaben doch mal die maximale Power der Cloud benötigt, ist das problemlos möglich.
Man hat also die volle Kontrolle:
- Lokal für Sensibles (Bilanzen, Mandantendaten, Strategisches)
- Cloud für Allgemeines (Textformulierungen, allgemeine Recherche, unkritische Aufgaben)
- Alles unter einer Oberfläche – keine Tool-Wechsel für die Nutzer
Grenzen und Ehrlichkeit: Was diese Lösung nicht kann
Keine Lösung ist perfekt. Hier die ehrlichen Grenzen:
Modell-Qualität
Lokale Open-Source-Modelle sind gut, aber (noch) nicht so gut wie ChatGPT, Gemini oder Claude. Für komplexe Reasoning-Aufgaben oder sehr nuancierte Texte merkt man den Unterschied. Allerdings: Für 80% der Finance-Aufgaben reichen die lokalen Modelle völlig aus.
Hardware-Anforderungen
Wer wirklich grosse Modelle lokal betreiben will, braucht entsprechende Hardware. Ein Standard-Office-Laptop reicht nicht. Die IT muss mitspielen und entsprechende Ressourcen bereitstellen.
Technisches Know-how
Das Setup erfordert grundlegende Kenntnisse in Docker, Netzwerkkonfiguration und idealerweise Python oder etwas Freude am Interagieren mit “Claude”. Für reine “Klick-und-fertig”-Erwartungen ist diese Lösung nichts. Es braucht jemanden, der sich mit der Technik beschäftigt.
Support und Wartung
Es gibt keinen Vendor-Support. Bei Problemen ist man auf Community-Foren, Dokumentation und eigenes Troubleshooting angewiesen. Für Unternehmen mit knappen IT-Ressourcen kann das ein Nachteil sein, aber auch hier kommt man ehrlicherweise mit Claude sehr weit. Es ist mittlerweilen einfach so.
Praxis-Tipps für den eigenen Proof of Concept
Wenn Sie diesen Weg selbst testen möchten, hier meine konkreten Empfehlungen:
Tipp 1: Starten Sie klein Beginnen Sie mit einem einfachen Setup: Ein lokaler Laptop mit Ollama und OpenWebUI. Testen Sie verschiedene Modelle (Llama 3, Mistral, Qwen). Erst wenn Sie verstanden haben, was funktioniert, gehen Sie in Richtung Netzwerk-Installation.
Tipp 2: Holen Sie die IT früh ins Boot Die Microsoft-SSO-Integration erfordert Zugriff auf Azure AD. Sprechen Sie früh mit der IT-Abteilung. Erklären Sie den Datenschutz-Vorteil, das öffnet Türen.
Tipp 3: Dokumentieren Sie alles Docker-Compose-Files, Konfigurationen, Zugangsdaten, alles gehört dokumentiert. Wenn Sie in den Ferien sind und etwas nicht funktioniert, muss jemand anderes nachvollziehen können, was Sie gebaut haben.
Tipp 4: Definieren Sie Use Cases vor dem Rollout Bevor Sie Kollegen Zugang geben, definieren Sie 2-3 konkrete Use Cases. “Hier ist eine KI, macht mal” funktioniert selten. “Hier ist ein Tool, das dir bei der Budget-Analyse hilft” funktioniert besser.
Tipp 5: Erwarten Sie keine Perfektion Lokale Modelle halluzinieren auch. Die Qualität schwankt je nach Aufgabe. Kommunizieren Sie das transparent. KI ist ein Assistent, kein Ersatz für Fachwissen.
Tipp 6: Planen Sie Zeit für Iteration ein Das erste Setup wird nicht perfekt sein. Planen Sie 2-3 Iterationsrunden ein, um basierend auf Feedback zu verbessern.
Fazit: Der erste Schritt zur souveränen KI-Nutzung
Dieses Experiment zeigt: Wir müssen nicht zwingend auf teure Enterprise-Lizenzen warten, um KI sicher im Team zu pilotieren. Mit Tools wie OpenWebUI, Ollama und einer sauberen Integration in das bestehende Microsoft-Login-System können wir Finance-Teams befähigen, KI zu nutzen ohne bei Compliance und Datenschutz Bauchschmerzen zu bekommen.
Ist es Aufwand? Ja. Braucht es technisches Know-how? Ja. Aber ist es machbar für jeden, der etwas technische Neugier mitbringt? Absolut.
Der grösste Gewinn liegt vielleicht gar nicht in der Technologie selbst, sondern in der Erkenntnis: Wir sind nicht abhängig von US-Cloud-Anbietern. Wir können unsere eigene, souveräne KI-Infrastruktur bauen. Und das ist im Finance-Bereich, wo Vertrauen und Datenschutz alles sind, ein enormer strategischer Vorteil.
Ich bleibe dran und werde über weitere Experimente berichten. Es bleibt spannend.
